早期的ReID研究大家还主要关注点在全局的global feature上,就是用整图得到一个特征向量进行图像检索。但是后来大家逐渐发现全局特征遇到了瓶颈,于是开始渐渐研究起局部的local feature。常用的提取局部特征的思路主要有图像切块、利用骨架关键点定位以及姿态矫正等等。
(1)图片切块是一种很常见的提取局部特征方式[12]。如下图所示,图片被垂直等分为若干份,因为垂直切割更符合我们对人体识别的直观感受,所以行人重识别领域很少用到水平切割。
之后,被分割好的若干块图像块按照顺序送到一个长短时记忆网络(Long short term memory network, LSTM),最后的特征融合了所有图像块的局部特征。但是这种缺点在于对图像对齐的要求比较高,如果两幅图像没有上下对齐,那么很可能出现头和上身对比的现象,反而使得模型判断错误。
(2)为了解决图像不对齐情况下手动图像切片失效的问题,一些论文利用一些先验知识先将行人进行对齐,这些先验知识主要是预训练的人体姿态(Pose)和骨架关键点(Skeleton) 模型。论文[13]先用姿态估计的模型估计出行人的关键点,然后用仿射变换使得相同的关键点对齐。如下图所示,一个行人通常被分为14个关键点,这14个关键点把人体结果分为若干个区域。为了提取不同尺度上的局部特征,作者设定了三个不同的PoseBox组合。之后这三个PoseBox矫正后的图片和原始为矫正的图片一起送到网络里去提取特征,这个特征包含了全局信息和局部信息。特别提出,如果这个仿射变换可以在进入网络之前的预处理中进行,也可以在输入到网络后进行。如果是后者的话需要需要对仿射变换做一个改进,因为传统的放射变化是不可导的。为了使得网络可以训练,需要引入可导的近似放射变化,在本文中不赘述相关知识。

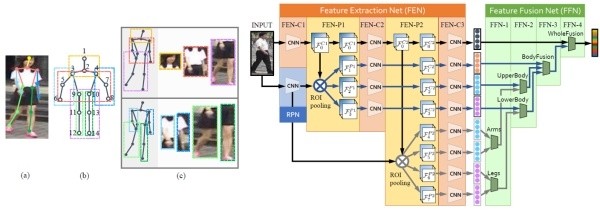
(3)CVPR2017的工作Spindle Net[14]也利用了14个人体关键点来提取局部特征。和论文[12]不同的是,Spindle Net并没有用仿射变换来对齐局部图像区域,而是直接利用这些关键点来抠出感兴趣区域(Region of interest, ROI)。Spindle Net网络如下图所示,首先通过骨架关键点提取的网络提取14个人体关键点,之后利用这些关键点提取7个人体结构ROI。网络中所有提取特征的CNN(橙色表示)参数都是共享的,这个CNN分成了线性的三个子网络FEN-C1、FEN-C2、FEN-C3。对于输入的一张行人图片,有一个预训练好的骨架关键点提取CNN(蓝色表示)来获得14个人体关键点,从而得到7个ROI区域,其中包括三个大区域(头、上身、下身)和四个四肢小区域。这7个ROI区域和原始图片进入同一个CNN网络提取特征。原始图片经过完整的CNN得到一个全局特征。三个大区域经过FEN-C2和FEN-C3子网络得到三个局部特征。四个四肢区域经过FEN-C3子网络得到四个局部特征。之后这8个特征按照图示的方式在不同的尺度进行联结,最终得到一个融合全局特征和多个尺度局部特征的行人重识别特征。
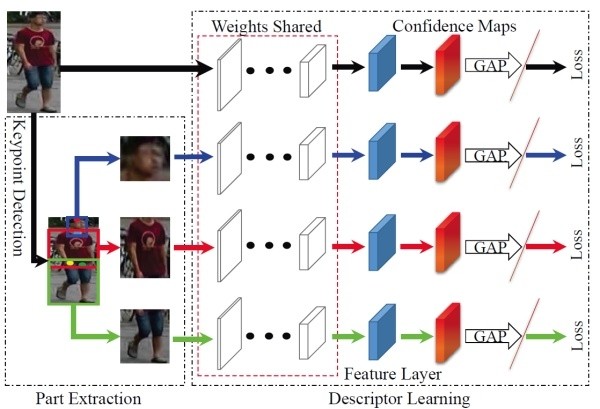
(4)论文[15]提出了一种全局-局部对齐特征描述子(Global-Local-Alignment Descriptor, GLAD),来解决行人姿态变化的问题。与Spindle Net类似,GLAD利用提取的人体关键点把图片分为头部、上身和下身三个部分。之后将整图和三个局部图片一起输入到一个参数共享CNN网络中,最后提取的特征融合了全局和局部的特征。为了适应不同分辨率大小的图片输入,网络利用全局平均池化(Global average pooling, GAP)来提取各自的特征。和Spindle Net略微不同的是四个输入图片各自计算对应的损失,而不是融合为一个特征计算一个总的损失。
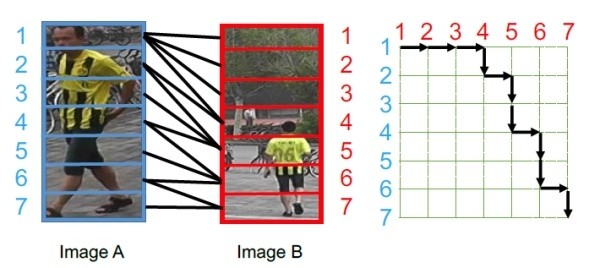
(5)以上所有的局部特征对齐方法都需要一个额外的骨架关键点或者姿态估计的模型。而训练一个可以达到实用程度的模型需要收集足够多的训练数据,这个代价是非常大的。为了解决以上问题,AlignedReID[16]提出基于SP距离的自动对齐模型,在不需要额外信息的情况下来自动对齐局部特征。而采用的方法就是动态对齐算法,或者也叫最短路径距离。这个最短距离就是自动计算出的local distance。
这个local distance可以和任何global distance的方法结合起来,论文[15]选择以TriHard loss作为baseline实验,最后整个网络的结构如下图所示,具体细节可以去看原论文。
4.基于视频序列的ReID方法目前单帧的ReID研究还是主流,因为相对来说数据集比较小,哪怕一个单GPU的PC做一次实验也不会花太长时间。但是通常单帧图像的信息是有限的,因此有很多工作集中在利用视频序列来进行行人重识别方法的研究[17-24]。基于视频序列的方法最主要的不同点就是这类方法不仅考虑了图像的内容信息,还考虑了帧与帧之间的运动信息等。
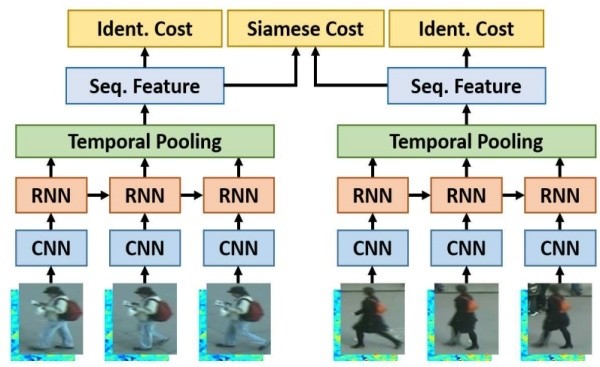
基于单帧图像的方法主要思想是利用CNN来提取图像的空间特征,而基于视频序列的方法主要思想是利用CNN 来提取空间特征的同时利用递归循环网络(Recurrent neural networks, RNN)来提取时序特征。上图是非常典型的思路,网络输入为图像序列。每张图像都经过一个共享的CNN提取出图像空间内容特征,之后这些特征向量被输入到一个RNN网络去提取最终的特征。最终的特征融合了单帧图像的内容特征和帧与帧之间的运动特征。而这个特征用于代替前面单帧方法的图像特征来训练网络。
视频序列类的代表方法之一是累计运动背景网络(Accumulative motion context network, AMOC)[23]。AMOC输入的包括原始的图像序列和提取的光流序列。通常提取光流信息需要用到传统的光流提取算法,但是这些算法计算耗时,并且无法与深度学习网络兼容。为了能够得到一个自动提取光流的网络,作者首先训练了一个运动信息网络(Motion network, Moti Nets)。这个运动网络输入为原始的图像序列,标签为传统方法提取的光流序列。如下图所示,原始的图像序列显示在第一排,提取的光流序列显示在第二排。网络有三个光流预测的输出,分别为Pred1,Pred2,Pred3,这三个输出能够预测三个不同尺度的光流图。最后网络融合了三个尺度上的光流预测输出来得到最终光流图,预测的光流序列在第三排显示。通过最小化预测光流图和提取光流图的误差,网络能够提取出较准确的运动特征。
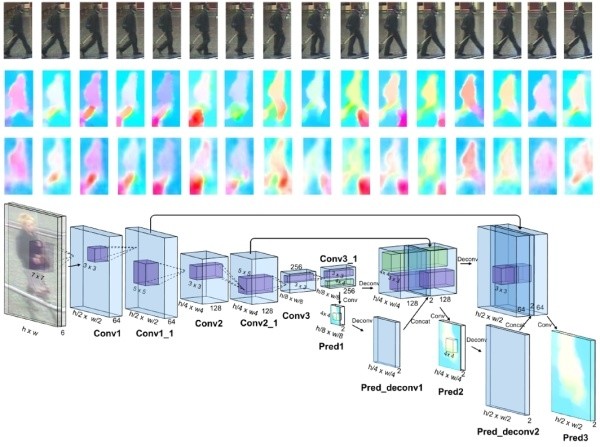
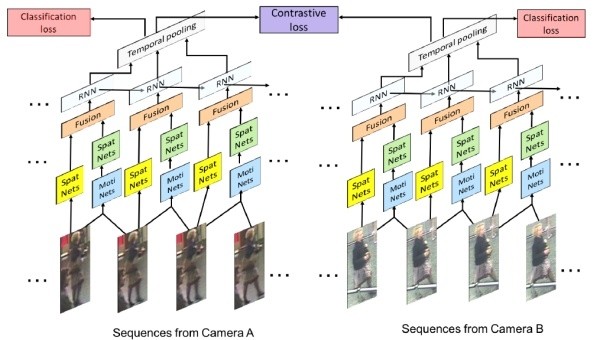
AMOC的核心思想在于网络除了要提取序列图像的特征,还要提取运动光流的运动特征,其网络结构图如下图所示。AMOC拥有空间信息网络(Spatial network, Spat Nets)和运动信息网络两个子网络。图像序列的每一帧图像都被输入到Spat Nets来提取图像的全局内容特征。而相邻的两帧将会送到Moti Nets来提取光流图特征。之后空间特征和光流特征融合后输入到一个RNN来提取时序特征。通过AMOC网络,每个图像序列都能被提取出一个融合了内容信息、运动信息的特征。网络采用了分类损失和对比损失来训练模型。融合了运动信息的序列图像特征能够提高行人重识别的准确度。
论文[24]从另外一个角度展示了多帧序列弥补单帧信息不足的作用,目前大部分video based ReID方法还是不管三七二十一的把序列信息输给网络,让网络去自己学有用的信息,并没有直观的去解释为什么多帧信息有用。而论文[24]则很明确地指出当单帧图像遇到遮挡等情况的时候,可以用多帧的其他信息来弥补,直接诱导网络去对图片进行一个质量判断,降低质量差的帧的重要度。
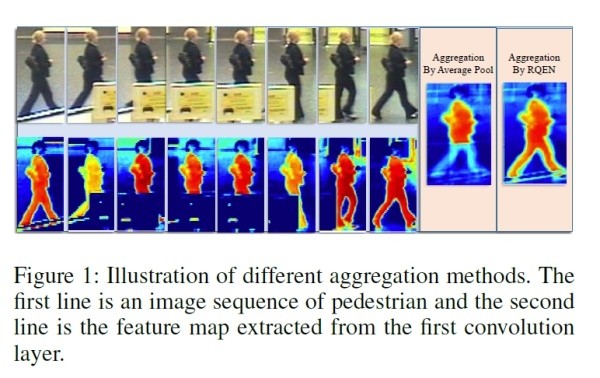
如上图,文章认为在遮挡较严重的情况下,如果用一般的pooling会造成attention map变差,遮挡区域的特征会丢失很多。而利用论文的方法每帧进行一个质量判断,就可以着重考虑那些比较完整的几帧,使得attention map比较完整。而关键的实现就是利用一个pose estimation的网络,论文叫做landmark detector。当landmark不完整的时候就证明存在遮挡,则图片质量就会变差。之后pose feature map和global feature map都同时输入到网络,让网络对每帧进行一个权重判断,给高质量帧打上高权重,然后对feature map进行一个线性叠加。思路比较简单但是还是比较让人信服的。
5.基于GAN造图的ReID方法
ReID有一个非常大的问题就是数据获取困难,截止CVPR18 deadline截稿之前,最大的ReID数据集也就小几千个ID,几万张图片(序列假定只算一张)。因此在ICCV17 GAN造图做ReID挖了第一个坑之后,就有大量GAN的工作涌现,尤其是在CVPR18 deadline截稿之后arxiv出现了好几篇很好的paper。
论文[25]是第一篇用GAN做ReID的文章,发表在ICCV17会议,虽然论文比较简单,但是作为挖坑鼻祖引出一系列很好的工作。如下图,这篇论文生成的图像质量还不是很高,甚至可以用很惨来形容。另外一个问题就是由于图像是随机生成的,也就是说是没有可以标注label可以用。为了解决这个问题,论文提出一个标签平滑的方法。实际操作也很简单,就是把label vector每一个元素的值都取一样,满足加起来为1。反正也看不出属于哪个人,那就一碗水端平。生成的图像作为训练数据加入到训练之中,由于当时的baseline还不像现在这么高,所以效果还挺明显的,至少数据量多了过拟合能避免很多。

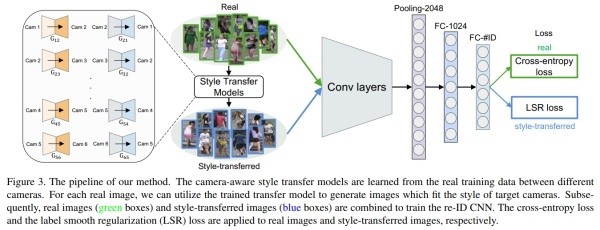
论文[26]是上一篇论文的加强版,来自同一个课题组。前一篇的GAN造图还是随机的,在这一篇中变成了可以控制的生成图。ReID有个问题就是不同的摄像头存在着bias,这个bias可能来自光线、角度等各个因素。为了克服这个问题,论文使用GAN将一个摄像头的图片transfer到另外一个摄像头。在GAN方面依然还是比较正常的应用,和前作不同的是这篇论文生成的图是可以控制,也就是说ID是明确的。于是标签平滑也做了改进,公式如下:
其中是ID的数量。是手动设置的平滑参数,当时就是正常的one-hot向量,不过由于是造的图,所以希望label不要这么hard,因此加入了一个平滑参数,实验表明这样做效果不错。最终整体的网络框架如下图:
除了摄像头的bias,ReID还有个问题就是数据集存在bias,这个bias很大一部分原因就是环境造成的。为了克服这个bias,论文[27]使用GAN把一个数据集的行人迁移到另外一个数据集。为了实现这个迁移,GAN的loss稍微设计了一下,一个是前景的绝对误差loss,一个是正常的判别器loss。判别器loss是用来判断生成的图属于哪个域,前景的loss是为了保证行人前景尽可能逼真不变。这个前景mask使用PSPnet来得到的,效果如下图。论文的另外一个贡献就是提出了一个MSMT17数据集,是个挺大的数据集,希望能够早日public出来。

ReID的其中一个难点就是姿态的不同,为了克服这个问题论文[28]使用GAN造出了一系列标准的姿态图片。论文总共提取了8个pose,这个8个pose基本涵盖了各个角度。每一张图片都生成这样标准的8个pose,那么pose不同的问题就解决。最终用这些图片的feature进行一个average pooling得到最终的feature,这个feature融合了各个pose的信息,很好地解决的pose bias问题。无论从生成图还是从实验的结果来看,这个工作都是很不错的。这个工作把single query做成了multi query,但是你没法反驳,因为所有的图都是GAN生成的。除了生成这些图需要额外的时间开销以外,并没有利用额外的数据信息。当然这个工作也需要一个预训练的pose estimation网络来进行pose提取。

总的来说,GAN造图都是为了从某个角度上解决ReID的困难,缺啥就让GAN来补啥,不得不说GAN还真是一个强大的东西。
后言:以上就是基于深度学习的行人重识别研究综述,选取了部分代表性的论文,希望能够帮助刚进入这个领域的人快速了解近几年的工作。当然还有很多优秀的工作没有放进来,ICCV17的ReID文章就有十几篇。这几年加起来应该有上百篇相关文章,包括一些无监督、半监督、cross-domain等工作都没有提到,实在精力和能力有限。
